urllib urllib是一个Python库,利用它可以实现HTTP请求的发送,我们要做的是指定请求的URL、请求头、请求体等信息。此外urllib还可以把服务器返回的对象转化为Python对象,通过该对象可以方便地获取响应的相关信息,如响应状态码、响应头、响应体。
request: 最基本的http请求模块,可以模拟请求的发送。
error: 异常处理模块。
parse: 一个工具模块。
robotparser: 主要用来识别网站的robots.txt文件,然后判断哪些网站可以爬,哪些网站不可以爬。
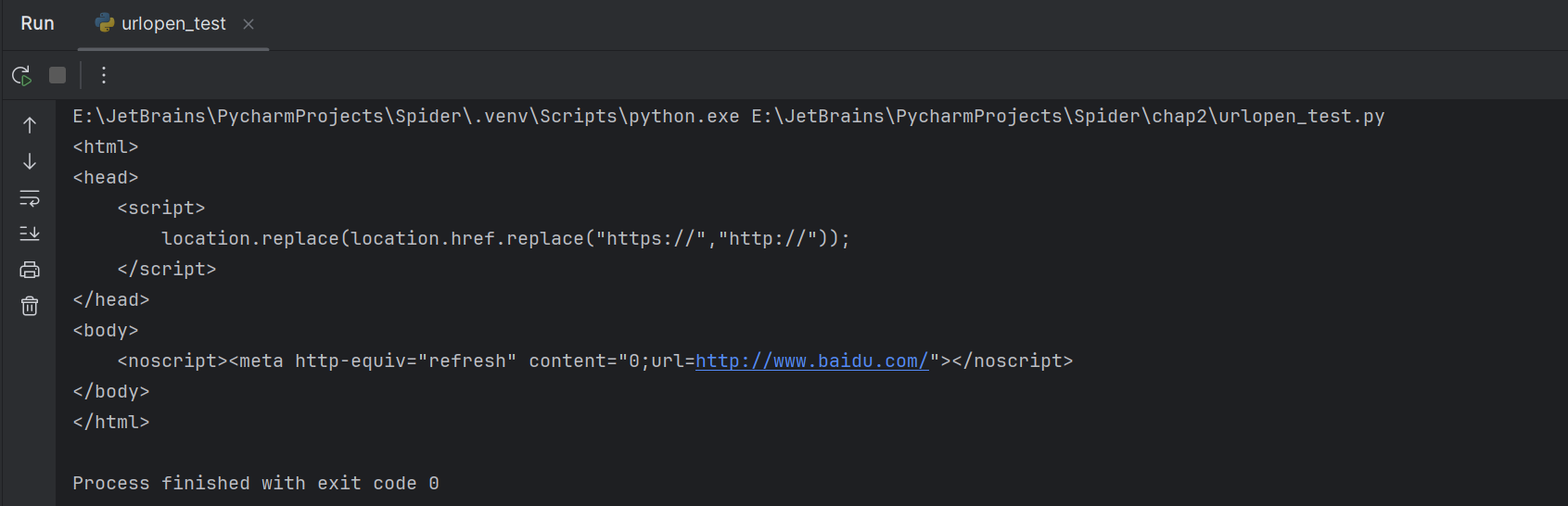
发送请求 urlopen urllib.request模块提供了最基本的构造HTTP请求的方法,利用这个模块可以模拟浏览器的请求发起过程。用百度测试
1 2 3 import urllib.requestresponse = urllib.request.urlopen('https://www.baidu.com' ) print (response.read().decode('utf-8' ))
response.read()方法
1 2 3 4 5 import urllib.requestresponse = urllib.request.urlopen('https://www.baidu.com' ) print (type (response))>>> <class 'http.client.HTTPResponse' >
这里响应的是HTTPResponse类型的对象,包含read、readinto、getheader、getheaders、fileno等方法。得到响应把它赋值给了response,可以通过response对象来调用哪些方法和属性。
打印响应的属性
1 2 3 4 5 6 import urllib.requestresponse = urllib.request.urlopen('https://www.baidu.com' ) print (response.status) //响应状态码print (response.getheaders()) //响应头的信息print (response.getheader("Server" )) //提供参数,获取响应头对应参数的信息print (response.read().decode('utf-8' ))
data参数 data参数可选。在添加该参数的时候,需要使用bytes方法将参数转化为字节流编码格式的内容,即bytes类型。如果传递了这个参数,那么它的请求方式就不再是GET而是POST了。https://www.httpbin.org ,它可以提供HTTP请求测试。本次请求的URL是 https://www.httpbin.org/post,这个连接可以测试POST请求,能够输出请求的一些信息,其中包含我们传递的data参数。
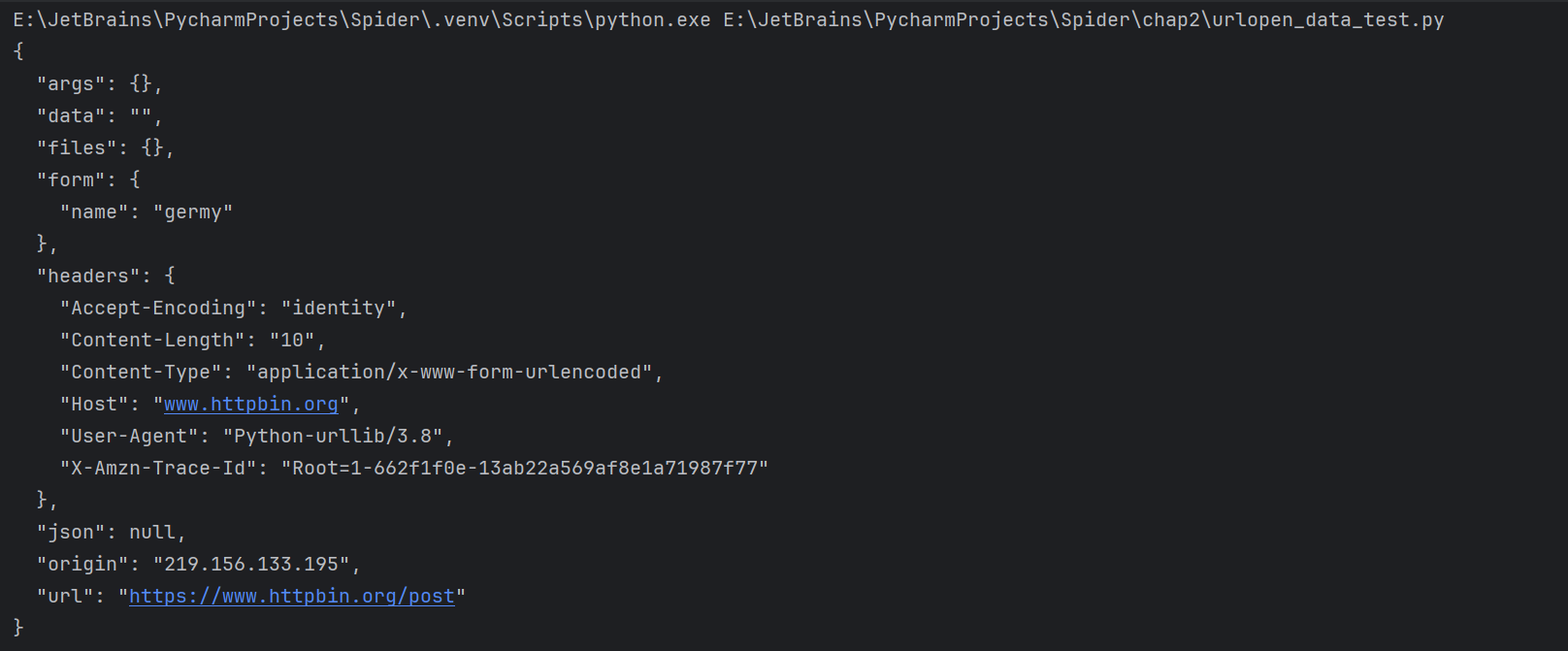
1 2 3 4 5 import urllib.requestimport urllib.parsedata = bytes (urllib.parse.urlencode({'name' :'germy' }),encoding='utf-8' ) response = urllib.request.urlopen('https://www.httpbin.org/post' ,data) print (response.read().decode('utf-8' ))
我们传递的参数出现在了form字段中,表明是模拟表单提交,以POST方式传输数据。
timeout参数 设置超时时间,单位是秒,如果请求超出了设置的这个时间,还没有得到响应,就会抛出异常,如果不指定这个参数,会使用全局默认时间。
1 2 3 4 import socketimport urllib.requestresponse = urllib.request.urlopen('https://www.httpbin.org/get' ,timeout=0.1 ) print (response.read().decode('utf-8' ))
可能会出现urllib.error.URLError: <urlopen error timed out>这种报错
实例
1 2 3 4 5 6 7 8 9 10 11 import socketimport urllib.requestimport urllib.parseimport urllib.errortry : response = urllib.request.urlopen('https://www.httpbin.org/get' ,timeout=0.1 ) except urllib.error.URLError as e: if isinstance (e.reason,socket.timeout): print ('Time Out' ) >>> Time Out
其他参数 context 参数,该参数必须是ssl.SSLContext类型,用来指定SSL的设置。cafile 和capate 这两个参数分别用来指定CA证书和其路径,在请求HTTPS连接时会用。
Request 利用urlopen发起的最基本的请求,那几个参数并不足以构建一个完整的请求。如果想往请求中加入Headers信息,就要利用更强大的Request类来构建请求了。
1 2 3 4 import urllib.requestrequest = urllib.request.Request('http://www.baidu.com' ) response = urllib.request.urlopen(request) print (response.read().decode('utf-8' ))
1 class urllib.request.Request(url,data=None,headers={},origin_req_host,unverifiable=False,method=None)
第一个参数url用于请求URL,是必传参数,其他都是可选参数。
1 2 3 4 5 6 7 8 9 from urllib import request,parseurl = 'http://www.httpbin.org/post' headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0' , 'Host' :'www.httpbin.org' } dict = {'name' :'germy' }data = bytes (parse.urlencode(dict ),encoding='utf-8' ) req = request.Request(url,data,headers,method='POST' ) response = request.urlopen(req) print (response.read().decode('utf-8' ))
传入4个参数构造了一个Request类,data用urlencode方法和bytes方法把字典数据转换成字节流格式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 { "args": {}, "data": "", "files": {}, "form": { "name": "germy" }, "headers": { "Accept-Encoding": "identity", "Content-Length": "10", "Content-Type": "application/x-www-form-urlencoded", "Host": "www.httpbin.org", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0", "X-Amzn-Trace-Id": "Root=1-662f5c7d-78dad94c612f72536858fcd6" }, "json": null, "origin": "219.156.133.195", "url": "http://www.httpbin.org/post" }
成功设置了data,headers,method
1 2 req=request.Request(url=url,data=data,method=method) req.add_header('User-Agent','xxxxx')
高级用法 学会构建请求之后,还有一些高级操作如Cookie处理、代理设置等,我们需要用Handler。Handler可以理解为各种处理器,有专门处理登录验证的、处理Cookie的、处理代理设置的。利用Handler,几乎可以实现HTTP请求中所有的功能。
HTTPDefaultErrorHandler用于处理HTTP响应错误,所有错误都会抛出HTTPError类型的异常。
HTTPRedirectHandler用于处理重定向。
HTTPCookieProcessor用于处理Cookie。
ProxyHandler用于设置代理,代理默认为空。
HTTPPasswordMgr用于管理密码,它维护着用户名密码的对照表。
HTTPBasicAuthHandle用于管理认证,如果一个链接在打开时需要认证,那么可以用这个类来解决认证问题。
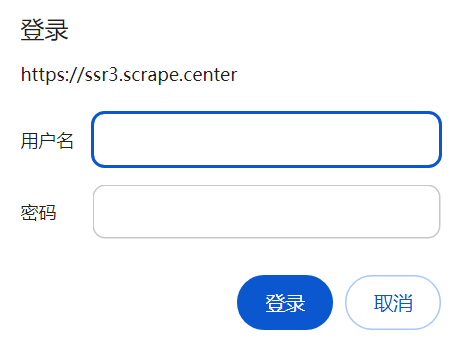
验证 在访问某些网站时,例如 https://ssr3.scrape.center ,可能会弹出认证窗口
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from urllib.request import HTTPBasicAuthHandler,HTTPPasswordMgrWithDefaultRealm,build_opener from urllib.error import URLError username = 'admin' password = 'admin' url="https://ssr3.scrape.center/" p=HTTPPasswordMgrWithDefaultRealm() p.add_password(None,url,username,password) auth_handler = HTTPBasicAuthHandler(p) opener = build_opener(auth_handler) try : result = opener.open(url) html = result.read().decode('utf-8') print(html) except URLError as e: print(e.reason)
这里首先实例化了一个HTTPBasicAuthHandler对象auth_handler,参数是HTTPPasswordMgrWithDefaultRealm对象,它利用add_passward方法添加用户名和密码,建立了一个用来处理验证的Handler类。
代理 添加代理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from urllib.error import URLError from urllib.request import ProxyHandler , build_opener proxy_handler = ProxyHandler( {'http' : 'http://127.0.0.1:8080', 'https' : 'https://127.0.0.1:8080'} ) opener = build_opener(proxy_handler) try: response = opener.open('https://www.baidu.com') print(response.read().decode('utf-8')) except URLError as e: print(e.reason)
在本地搭建HTTP代理,让其运行在8080端口上。使用了ProxyHandler,其参数是一个字典,键名是协议类型,键值是代理链接,可以添加多个代理。利用这个Handler和build_opener方法构建了一个Opener,之后发送请求即可。
Cookie 处理Cookie需要用到相关的Handler。
1 2 3 4 5 6 7 8 import http.cookiejar,urllib.request cookie = http.cookiejar.CookieJar() handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open('https://www.baidu.com') for item in cookie: print(item.name+"="+item.value)
先声明CookieJar对象。然后利用HTTPCookieProcessor构建一个Handler,再利用build_opener方法构建Opener,执行open函数即可。
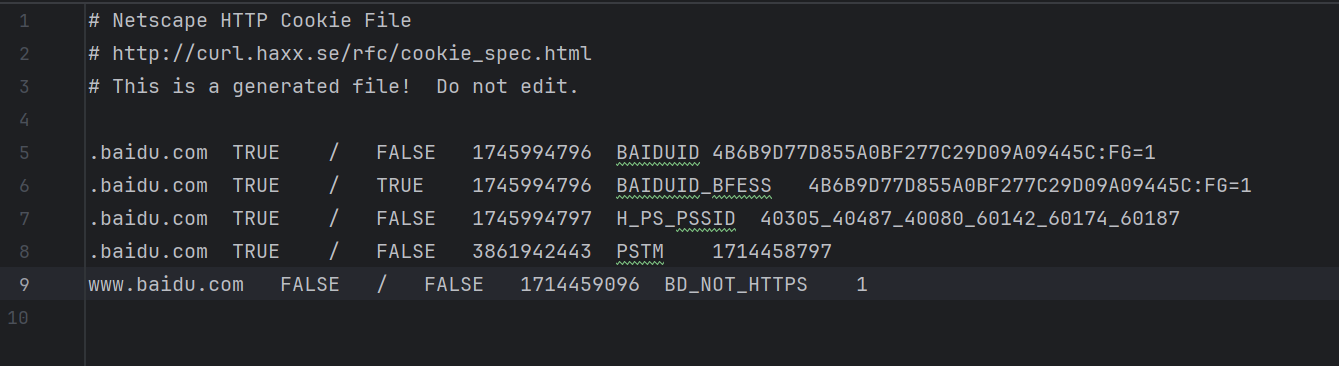
1 2 3 4 5 6 7 8 import urllib.request,http.cookiejar filename = 'cookies.txt' cookie = http.cookiejar.MozillaCookieJar(filename) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open('https://www.baidu.com') cookie.save(ignore_discard=True,ignore_expires=True)
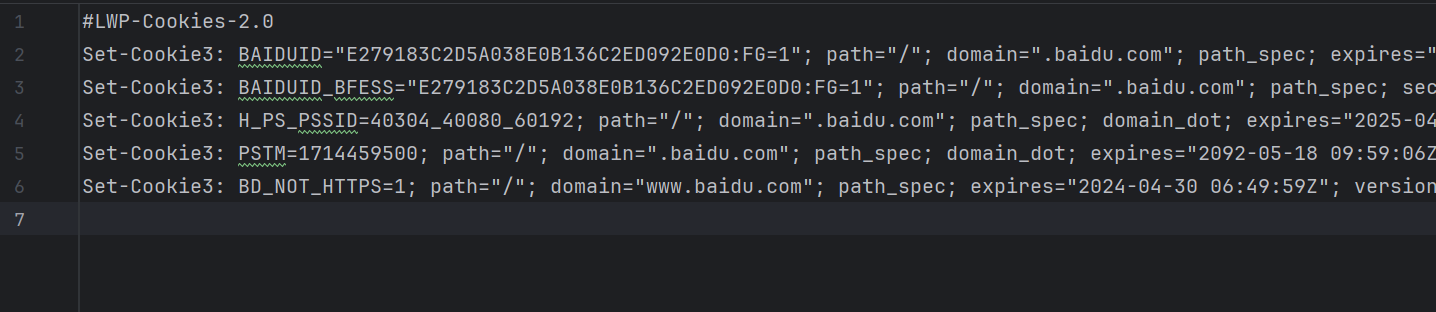
这时将CookieJar换成MozillaCookieJar,它会在生成文件时用到,是CookieJar的子类,用来处理跟Cookie和文件相关的事件,如读取和保存Cookie可以将Cookie保存成Mozilla型浏览器的Cookie格式。cookie = http.cookiejar.LWPCookieJar(filename)
1 2 3 4 5 6 7 8 import urllib.request,http.cookiejar cookie = http.cookiejar.LWPCookieJar() cookie.load('cookies.txt',ignore_discard=True,ignore_expires=True) handler = urllib.request.HTTPCookieProcessor(cookie) opener = urllib.request.build_opener(handler) response = opener.open('https://www.baidu.com') print(response.read().decode('utf-8'))
这里调用load方法来读取本地的Cookie文件,获取Cookie的内容。这样做的前提是我们已经生成了LWPCookieJar格式的Cookie,并保存成了文件,读取了Cookie之后,用同样的方法构建Handler类和Opener类即可完成操作。
处理异常 URLError URLError类来自urllib库的error模块,继承自OSError类,是error异常模块的基类,由request模块产生的异常可以通过捕获这个类来处理。
1 2 3 4 5 6 7 from urllib import request,errortry : response = request.urlopen('https://blttttt.com/404' ) except error.URLError as e: print (e.reason) >>> [Errno 11001 ] getaddrinfo failed
我们访问了一个不存在的页面,是会报错的,但是通过捕获URLError这个异常,没有直接报错,而是输出了报错的原因,可以避免程序异常终止。
HTTPError HTTPError是URLError的子类,专门用来处理HTTP请求的错误,例如认证请求失败。
code
reason
headers
实例
1 2 3 4 5 from urllib import request,errortry : response = request.urlopen('https://cuiqingcai.com/404' ) except error.HTTPError as e: print (e.reason,e.code,e.headers,sep='\n' )
运行结果
1 2 3 4 5 6 7 8 9 from urllib import request,errortry : response = request.urlopen('https://cuiqingcai.com/404' ) except error.HTTPError as e: print (e.reason,e.code,e.headers,sep='\n' ) except error.URLError as e: print (e.reason) else : print ("Request succeeded" )
这样可以先捕获HTTPError,捕获它的错误原因、状态码、请求头信息。如果不是HTTPError异常,就会捕获URLError异常,输出错误原因。最后用else语句来处理正常的逻辑。
1 2 3 4 5 6 7 8 9 10 11 12 import socketimport urllib.requestimport urllib.errortry : response = urllib.request.urlopen('https://cuiqingcai.com/404' ,timeout=0.01 ) except urllib.error.URLError as e: print (type (e.reason)) if isinstance (e.reason,socket.timeout): print ('TIME OUT' ) >>> <class 'socket.timeout' > TIME OUT
reason的类型是socket.timeout类,这里使用了isinstance方法来判断它的类型。
解析链接 urllib库里还提供了parse模块,这个模块定义了处理URL的标准接口,如实现URL各部分的抽取、合并以及转换。它支持如下协议处理:file、ftp、gopher、hdl、http、https、imap、mailto、mms、news、nntp、prospero、rsync、rtsp、rtspu、sftp、sip、sips、snews、svn、svn+ssh、telnet和wais。
urlparse 这个方法可以实现url的识别和分段
1 2 3 4 5 6 7 8 from urllib.parse import urlparse result = urlparse('https://www.baidu.com/index.html;user?id=5#comment') print(type(result)) print(result) >>> <class 'urllib.parse.ParseResult'> ParseResult(scheme='https', netloc='www.baidu.com', path='/index.html', params='user', query='id=5', fragment='comment')
解析的结果是ParseResult类型的对象,包含6部分,分别是scheme、netloc、path、params、query、fragment。https://www.baidu.com/index.html;user?id=5#comment://前面的内容就是scheme,代表协议。第一个/符号前面便是netloc,即域名;后面是path,访问路径。分号;后面是params,参数。问号?后面是查询条件query,一般用作GET类型的URL。井号#后面是锚点fragment,用于直接定位页面内部的下拉位置。scheme://netloc/path;params?quert#fragment,一个标准的URL都会符合这个规则,利用urlparse方法就可以将它拆分开来。urllib.parse.urlparse(urlstring,scheme='',allow_fragment=True)
urlstring:
scheme:
allow_fragment:
urlunparse 此方法用于构造URL。接收的参数是一个可迭代对象,其长度必须是6,否则会抛出参数数量不足或者过多的问题。
1 2 3 4 5 from urllib.parse import urlunparsedata = ['https' ,'www.baidu.com' ,'index.html' ,'uesr' ,'a=6' ,'comment' ] print (urlunparse((data)))>>> https://www.baidu.com/index.html;uesr?a=6
这里的参数使用的data列表类型。也可以使用其他类型,如元组或特定的数据结构。
urlsplit 此方法和urlparse类似,不过它不再单独解析params这部分(params会合并到path中),只返回5个结果。
1 2 3 4 5 6 7 from urllib.parse import urlsplitresult = urlsplit('https://www.baidu.com/index.html;user?id=5#comment' ) print (result)print (type (result))>>> SplitResult(scheme='https' , netloc='www.baidu.com' , path='/index.html;user' , query='id=5' , fragment='comment' ) <class 'urllib.parse.SplitResult' >
返回的结果是SplitResult,其实也是元组,可以通过属性取其值,也可以通过索引取值。
1 2 3 4 5 from urllib.parse import urlsplitresult = urlsplit('https://www.baidu.com/index.html;user?id=5#comment' ) print (result.scheme,result[0 ])>>> https https
urlunsplit 与urlunparse类似,也是将链接各部分组合成完整链接的方法,传入的参数是可迭代对象,如列表,元组,参数长度必须是5。
1 2 3 4 5 from urllib.parse import urlunsplitdata=['https' ,'www.baidu.com' ,'index.html' ,'a=6' ,'comment' ] print (urlunsplit(data))>>> https://www.baidu.com/index.html?a=6
urljoin urlunparse和urlunsplit方法都可以完成链接的合并,但前提是有特定的对象,链接的每一部分要清晰分开。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 from urllib.parse import urljoin print(urljoin('https://www.baidu.com', 'FAQ.html')) print(urljoin('https://www.baidu.com', 'https://cuiqingcai.com/FAQ.html')) print(urljoin('https://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html')) print(urljoin('https://www.baidu.com/about.html', 'https://cuiqingcai.com/FAQ.html?question=2')) print(urljoin('https://www.baidu.com?wd=abc', 'https://cuiqingcai.com/index,php')) print(urljoin('https://www.baidu.com', '?category=2#comment')) print(urljoin('www.baidu.com', '?category=2#comment')) print(urljoin('www.baidu.com#comment', '?caetgory=2')) >>> https://www.baidu.com/FAQ.html https://cuiqingcai.com/FAQ.html https://cuiqingcai.com/FAQ.html https://cuiqingcai.com/FAQ.html?question=2 https://cuiqingcai.com/index,php https://www.baidu.com?category=2#comment www.baidu.com?category=2#comment www.baidu.com?caetgory=2
可以发现,base_url提供了scheme、netloc和path。如果新链接不存在这三项,就进行补充,如果存在,base_url是不起作用的。
urlencode 它在构造GET请求参数的时候非常有用。
1 2 3 4 5 6 7 8 9 10 from urllib.parse import urlencodeparams={ 'name' :'germy' , 'age' :25 } base_url = 'http://www.baidu.com?' url=base_url+urlencode(params) print (url)>>> http://www.baidu.com?name=germy&age=25
先声明了一个字典params,用于将参数显示出来,然后调用urlencode方法将params序列化为GET请求的参数。
parse_qs 有了序列化就会有反序列化。利用parse_qs方法,可以将一串GET请求参数转回字典。
1 2 3 4 5 from urllib.parse import parse_qsquery = 'name=germy&age=25' print (parse_qs(query))>>> {'name' : ['germy' ], 'age' : ['25' ]}
可以看到URL的参数车公共转换为了字典类型。
查询字符串是 URL 中 ? 符号后的部分,通常用于在 HTTP 请求中传递参数。
parse_qsl 此方法用于将参数转化为由元组组成的列表:
1 2 3 4 5 from urllib.parse import parse_qslquery = 'name=germy&age=25' print (parse_qsl(query))>>> [('name' , 'germy' ), ('age' , '25' )]
运行结果是一个列表,该列表中的每一个元素是一个元组,元组第一个内容是参数名,第二个内容是参数值。
quote 此方法可以将内容转化为URL编码的格式。当URL中带有中文参数的时候,有可能导致乱码,使用quote可以将中文字符转化为URL编码。
1 2 3 4 5 6 from urllib.parse import quotekeyword = '壁纸' url='http://www.baidu.com/s?wd=' +quote(keyword) print (url)>>> http://www.baidu.com/s?wd=%E5%A3%81 %E7%BA%B8
unquote 它可以进行URL解码。
1 2 3 4 5 from urllib.parse import unquoteurl = 'http://www.baidu.com/s?wd=%E5%A3%81%E7%BA%B8' print (unquote(url))>>> http://www.baidu.com/s?wd=壁纸
分析Robots协议 利用urllib库的robotparser模块,可以分析网站的Robots协议。
Robots协议 该协议也称爬虫协议或机器人协议,全名是网络爬虫排除标准。来告诉爬虫和搜索引擎哪些页面可以抓取,哪些不可以。通常有一个叫robots.txt的文本文件,一般在网站的根目录下。
robotparser 使用robotparser模块来解析robots.txt文件。该模块提供了一个RobotFileParser,它可以根据某网站的robots.txt文件判断一个爬取爬虫是否有权限爬取这个网页。urllib.robotparser.RobotFileParser(url='')
set_url:
read:
parse:
can_fetch:
mtime:
modified:
首先创建一个RobotFileParser对象rp,然后通过set_url方法设置robots.txt文件的链接。利用can_fetch方法判断网页是否可以被抓取。
1 2 3 4 5 6 7 8 9 10 11 from urllib.robotparser import RobotFileParserrp = RobotFileParser() rp.set_url("https://www.baidu.com/robots.txt" ) rp.read() print (rp.can_fetch('Baiduspider' ,'https://www.baidu.com' ))print (rp.can_fetch('Baiduspider' ,'https://www.baidu.com/homepage/' ))print (rp.can_fetch('Googlebot' ,'https://www.baidu.com/homepage/' ))>>> True True False
1 2 3 4 5 6 7 8 9 10 11 12 from urllib.request import urlopenfrom urllib.robotparser import RobotFileParserrp = RobotFileParser() rp.parse(urlopen('https://www.baidu.com/robots.txt' ).read().decode('utf-8' ).split('\n' )) print (rp.can_fetch('Baiduspider' ,'https://www.baidu.com' ))print (rp.can_fetch('Baiduspider' ,'https://www.baidu.com/homepage/' ))print (rp.can_fetch('Googlebot' ,'https://www.baidu.com/homepage/' ))>>> True True False
requests的使用 requests相比于urllib更加方便。
准备 首先确保安装了requests库,若未安装,使用pip3安装:pip3 install requests
实例 在urllib库中的urlopen方法实际上是以GET请求方式请求网页的,requests库中相应的方法就是get方法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import requestsresponse = requests.get('http://www.baidu.com' ) print (type (response))print (response.status_code)print (type (response.text))print (response.text[:100 ])print (response.cookies)>>> <class 'requests.models.Response' > 200 <class 'str' > <!DOCTYPE html><!--STATUS OK--><html><head><meta http-equiv="Content-Type" content="text/html;charse <RequestsCookieJar[<Cookie BAIDUID=1C74878EE150BFF62131B72042A1460F:FG=1 for .baidu.com/>, <Cookie BAIDUID_BFESS=1C74878EE150BFF62131B72042A1460F:FG=1 for .baidu.com/>, <Cookie BIDUPSID=1C74878EE150BFF62131B72042A1460F for .baidu.com/>, <Cookie H_PS_PSSID=40304_40499_40446_40080 for .baidu.com/>, <Cookie PSTM=1714996509 for .baidu.com/>]>
这里调用get方法实现了与urlopen方法相同的操作,返回一个Response对象,将其存放在变量response中,然后输出响应的类型,状态码,响应体的类型,内容,以及Cookie。
GET请求 利用requests库构建GET请求的方法。
基本实例 构建简单GET请求,请求链接为https://www.httpbin.org/get,该网站会判断客户端发起的请求是否为get请求,如果是,那么它将返回相应的请求信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import requestsurl = 'https://www.httpbin.org/get' r=requests.get(url) print (r.text)>>> { "args" : {}, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Host" : "www.httpbin.org" , "User-Agent" : "python-requests/2.31.0" , "X-Amzn-Trace-Id" : "Root=1-6638c88c-656171973be54b8465b565d1" }, "origin" : "219.156.133.195" , "url" : "https://www.httpbin.org/get" }
成功发起了GET请求,返回结果中包含请求头、URL、IP等信息。https://www.httpbin.org/get?name=germy&age=25,但是这样写稍有麻烦,其实可以利用params参数直接传递这种信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import requestsdata={ 'name' :'germy' , 'age' :25 } url = 'https://www.httpbin.org/get' response = requests.get(url, params=data) print (response.text)>>> { "args" : { "age" : "25" , "name" : "germy" }, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Host" : "www.httpbin.org" , "User-Agent" : "python-requests/2.31.0" , "X-Amzn-Trace-Id" : "Root=1-6638ca91-53eeec34391520830e2e1c8a" }, "origin" : "219.156.133.195" , "url" : "https://www.httpbin.org/get?name=germy&age=25" }
这样就把URL参数以字典的形式传给get方法的params参数,通过返回信息可以判断,请求链接自动被构造成了https://www.httpbin.org/get?name=germy&age=25,就不用自己构造URL了。
1 2 3 4 5 6 7 8 9 10 11 12 import requestsdata={ 'name' :'germy' , 'age' :25 } url = 'https://www.httpbin.org/get' response = requests.get(url, params=data) print (type (response.json()))print (response.json())>>> <class 'dict' > {'args' : {'age' : '25' , 'name' : 'germy' }, 'headers' : {'Accept' : '*/*' , 'Accept-Encoding' : 'gzip, deflate' , 'Host' : 'www.httpbin.org' , 'User-Agent' : 'python-requests/2.31.0' , 'X-Amzn-Trace-Id' : 'Root=1-6638cd0c-14525f1e05304540064c24db' }, 'origin' : '219.156.133.195' , 'url' : 'https://www.httpbin.org/get?name=germy&age=25' }
调用json方法可以将结果(JSON格式字符串)转化为字典。
对于上面的请求得到的响应,如果直接用print将响应的对象打印输出,得到的会是什么,我试了下,请求成功<Response [200]>,请求失败<Response [404]>
抓取网页 以https://ssr1.scrape.center为例,往代码里加一点提取信息的逻辑:
1 2 3 4 5 6 7 8 9 10 11 import reimport requestsurl = 'https://ssr1.scrape.center' response = requests.get(url) pattern = re.compile ('<h2.*?>(.*?)</h2>' ,re.S) titles = re.findall(pattern,response.text) print (titles)>>> ['霸王别姬 - Farewell My Concubine' , '这个杀手不太冷 - Léon' , '肖申克的救赎 - The Shawshank Redemption' , '泰坦尼克号 - Titanic' , '罗马假日 - Roman Holiday' , '唐伯虎点秋香 - Flirting Scholar' , '乱世佳人 - Gone with the Wind' , '喜剧之王 - The King of Comedy' , '楚门的世界 - The Truman Show' , '狮子王 - The Lion King' ]
这里提取出了所有的电影标题,只需一个最基本的抓取和提取流程即可完成。
抓取二进制数据 上面例子抓取的是网站页面,返回的是HTML文档。
1 2 3 4 5 import requestsurl = 'https://scrape.center/favicon.ico' response = requests.get(url) print (response.text)print (response.content)
这里response.text的运行结果是一串乱码,而response.content的运行结果是bytes类型的数据。
bytes类型的数据前面会带有一个b,也称为“字节串”的格式,字节串是由一系列字节组成的,每个字节可以表示一个字符或者数据的一部分。在Python中,字节串通常用单引号或双引号括起来,并且字节串中的每个字节用两个十六进制数表示。
可以将图片的二进制数据保存下来。
1 2 3 4 5 import requestsurl = 'https://scrape.center/favicon.ico' response = requests.get(url) with open ('favicon.ico' , 'wb' ) as f: f.write(response.content)
使用open方法,以二进制写的形式打开文件,向文件里写入二进制数据。
添加请求头 在发起HTTP请求的时候,会有一个请求头Request Headers,我们可以通过设置headers参数完成。
1 2 3 4 5 6 7 import requestsheaders={ 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36' } url = 'https://ssr1.scrape.center/' response = requests.get(url, headers=headers) print (response.text)
也可以在headers参数中添加其他字段信息。
POST请求 实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import requestsdata={ 'name' :'admin' , 'age' :25 } url = 'https://httpbin.org/post' response = requests.post(url,data=data) print (response.text)>>> { "args" : {}, "data" : "" , "files" : {}, "form" : { "age" : "25" , "name" : "admin" }, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Content-Length" : "17" , "Content-Type" : "application/x-www-form-urlencoded" , "Host" : "httpbin.org" , "User-Agent" : "python-requests/2.31.0" , "X-Amzn-Trace-Id" : "Root=1-6639927b-00d275d24c6775e71e150ebb" }, "json" : null, "origin" : "219.156.133.195" , "url" : "https://httpbin.org/post" }
form部分就是提交的数据,证明POST请求成功发送。
响应 请求发送后会得到响应。上面实例中,用的是text和content获取了响应的内容,还有很多属性
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import requestsurl = ('http://ssr1.scrape.center/' ) response = requests.get(url) print (type (response.status_code),response.status_code) //状态码print (type (response.headers),response.headers) //响应头print (type (response.cookies),response.cookies) //cookiesprint (type (response.url),response.url) //URLprint (type (response.history),response.history) //请求历史>>> <class 'int' > 200 <class 'requests.structures.CaseInsensitiveDict' > {'Date' : 'Tue, 07 May 2024 02:40:47 GMT' , 'Content-Type' : 'text/html; charset=utf-8' , 'X-Frame-Options' : 'DENY' , 'X-Content-Type-Options' : 'nosniff' , 'Expires' : 'Tue, 07 May 2024 02:45:59 GMT' , 'Strict-Transport-Security' : 'max-age=15724800; includeSubDomains' , 'Server' : 'Lego Server' , 'X-Cache-Lookup' : 'Cache Miss, Cache Miss' , 'Cache-Control' : 'max-age=600' , 'Age' : '0' , 'Content-Length' : '41667' , 'X-NWS-LOG-UUID' : '10330054940065279203' , 'Connection' : 'keep-alive' } <class 'requests.cookies.RequestsCookieJar' > <RequestsCookieJar[]> <class 'str' > https://ssr1.scrape.center/ <class 'list' > [<Response [302 ]>]
这里面headers和cookies这两个属性的结果分别是CaseInsensitiveDict和RequestsCookieJar类型的对象。200表示响应没有问题,而我们可以通过判断这个数字来确认爬虫是否爬取成功。
1 2 3 4 5 6 import requestsurl = 'https://ssr1.scrape.center/' response = requests.get(url) exit() if not response.status_code == requests.codes.ok else print ('Request Successfully' ) >>> Request Successfully
通过比较返回码和内置的表示成功的状态码,保证得到了正常响应,如果是就输出请求成功的消息,否则程序终止运行,用requests.codes.ok得到的成功状态码是200。
高级用法 文件上传 requests库可以模拟提交一些数据。也可以上传文件。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import requestsurl = 'https://httpbin.org/post' file = {'favicon.ico' : open ('favicon.ico' ,'rb' )} reponse = requests.post(url, files=file) print (reponse.text)>>> { "args" : {}, "data" : "" , "files" : { "favicon.ico" : "data:application/octet-stream;base64,AAAB..." }, "form" : {}, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Content-Length" : "4440" , "Content-Type" : "multipart/form-data; boundary=5dc8b6473c0c05dc184c55876cebce25" , "Host" : "httpbin.org" , "User-Agent" : "python-requests/2.31.0" , "X-Amzn-Trace-Id" : "Root=1-66399eb4-6599df655be9cf0a6a9ac001" }, "json" : null, "origin" : "219.156.133.195" , "url" : "https://httpbin.org/post" }
上传文件后,网站返回响应,响应中包含files字段和form字段,而form字段是空的,说明文件上传部分会单独用一个files字段来标识。
Cookie设置 前面使用过urllib库处理Cookie,写法较为复杂,而用requests库,获取和设置Cookie只需一部即可完成。
1 2 3 4 5 6 7 8 9 10 11 12 13 import requestsurl = 'https://www.baidu.com/' response = requests.get(url) print (response.cookies)for key, value in response.cookies.items(): print (key+'=' +value) >>> <RequestsCookieJar[<Cookie BAIDUID=0F50E1FD0E238874BD72A86D327F65CF:FG=1 for .baidu.com/>, <Cookie BAIDUID_BFESS=0F50E1FD0E238874BD72A86D327F65CF:FG=1 for .baidu.com/>, <Cookie H_PS_PSSID=40300_40079_40463_60174 for .baidu.com/>, <Cookie PSTM=1715055521 for .baidu.com/>, <Cookie BD_NOT_HTTPS=1 for www.baidu.com/>]> BAIDUID=070B4458EAF888B767A06FC7F52B6DE1:FG=1 BAIDUID_BFESS=070B4458EAF888B767A06FC7F52B6DE1:FG=1 H_PS_PSSID=40303_40080_60174 PSTM=1715054787 BD_NOT_HTTPS=1
这里先调用cookies属性,成功得到Cookie,发现它属于RequestsCookieJar类型。然后调用items方法将Cookie转化为由元组组成的列表,遍历输出每一个Cookie条目的名称和值,实现对Cookie的遍历和解析。
1 2 3 4 5 6 7 import requestsheaders = { 'Cookie' : '_octo=GH1.1.1020779121.1709874774; _device_id=e5c616e3c9807057e79266383da8cd61; saved_user_sessions=155144413%3AetQxEGfBoTvbxcQPOuPZ0WyHSskj5GsMfXA2k8JqGVOz4pv0; user_session=etQxEGfBoTvbxcQPOuPZ0WyHSskj5GsMfXA2k8JqGVOz4pv0; __Host-user_session_same_site=etQxEGfBoTvbxcQPOuPZ0WyHSskj5GsMfXA2k8JqGVOz4pv0; logged_in=yes; dotcom_user=blttttt; has_recent_activity=1; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; preferred_color_mode=light; tz=Asia%2FShanghai; _gh_sess=cscvLFSGJcf6AUPq6fzQjoyyl0O89JlmxwVkS1%2BaEXzwsS5bDp%2FKxbAGbdkfKGN2PeDMiLcD2%2BnXCaJiYkjRjAncjALoQ0yR0XMFkNlI08mU2uBAY%2BO0eHJ78vnRiiRutYVCkBPJAQF0oKQ8P46vwW1esYkG3X7Hfs2scPXyDm5sUkW0AC%2B%2B4Xg4yyjQ2VMD96gSpB0SUk8CMugT4GaYSQ4jWzSys%2BffoehUzl0fC76EAhvzT7X7fw5Oa4c7NKoGSz4xn6DXMl8ZaoK%2F7a32i%2FPwYplpfpcd8k%2By36Q%2F533m23P8dVyB3SMO2UZRdIFTUbTi7wFomjcSvbIFJ8lW%2BNMtuYrrz9TZ8X90K1gdDzi4KcmCSXzXcbY25E%2BDMlco%2BmfPtPPax1%2BIaoGu5HYTpM2IAkRDheNvdzHE4pbBPQbdJlx4p6V1R9MWYVm3iKM1Jx6gkPfm92%2BcbznQ4AItn4%2BV40z7Aj4QnV7gG6c8lkyeOhRjVls9s%2F%2BrhDwkHMPjxDpRzruGN6YEPo%2F7X8gt4uIspHA0d4z%2BnNbR1mloiPXw%2B1EJ6gqCog%3D%3D--8YfmSu%2BHtVUuakSu--kppLpsZaDcPEkIPLocCpMA%3D%3D' } url = ('https://github.com/' ) response = requests.get(url,headers=headers) print (response.text)
结果中包含了登录才能有的信息,其中包含用户名信息。
1 2 3 4 5 6 7 8 9 10 11 12 13 import requestscookies = '_octo=GH1.1.1020779121.1709874774; _device_id=e5c616e3c9807057e79266383da8cd61; saved_user_sessions=155144413%3AetQxEGfBoTvbxcQPOuPZ0WyHSskj5GsMfXA2k8JqGVOz4pv0; user_session=etQxEGfBoTvbxcQPOuPZ0WyHSskj5GsMfXA2k8JqGVOz4pv0; __Host-user_session_same_site=etQxEGfBoTvbxcQPOuPZ0WyHSskj5GsMfXA2k8JqGVOz4pv0; logged_in=yes; dotcom_user=blttttt; has_recent_activity=1; color_mode=%7B%22color_mode%22%3A%22auto%22%2C%22light_theme%22%3A%7B%22name%22%3A%22light%22%2C%22color_mode%22%3A%22light%22%7D%2C%22dark_theme%22%3A%7B%22name%22%3A%22dark%22%2C%22color_mode%22%3A%22dark%22%7D%7D; preferred_color_mode=light; tz=Asia%2FShanghai; _gh_sess=blrf5T4EJEg6JJ50EPrvPOFUhj0hBcd1MbdCCIQc8MS8Fe03V4WSkKIGvUY08G9m%2B4kh1Ir1%2F5fjayGfZFgwiz34xSZrtbWxNO6%2BVWD8yVdBxZYwmE%2ByX1ckwBVTlhVzWjuIg4cRuFc7Cf2a%2BEjNyWZ1SGWiEFqkBI4%2BNBFFWjySrCv8%2Bprb%2FGE6PYp5yMj5ErqhtrIprbxYYLeZujlF2xZKEtO5HEE%2FML%2BkhPd3zelGQ1xfsQCDZCtGMKzBl096OovkfZGd2neqwvadIN5BFbtXr%2F0Qrg0l5%2FgKZivdxH0FcFWjbbh6vBYC1Wdq6ddLAmtoK5tkzf65szPCym4wJWK8BHH5ui1g6gR2jCrKggtk7XDYJ%2FgfRdRFFhOFodqyUTAwliztTaEUqsZx10xvLGSzOa76fWfqN5DOktKMUqEVPi6RwRejzb2hf6CxNQ4fr1kR348GyuyNrQGpAi0%2BFod2%2B7r4VtIRXPmLX%2FhMLZqC4%2BMRiM1S9i3IeQdhj%2BF%2Bu1VBLuvVlg0hKX3xxm449GFW0tBXk345dTu89MLffCFI29X%2BUXV8jA%3D%3D--L4G%2B56Y9nCQAoeYL--nvFWkVjJSzdHJtWrW%2FW%2F4Q%3D%3D' jar = requests.cookies.RequestsCookieJar() headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36' } url = ('https://github.com/' ) for cookie in cookies.split(';' ): key, value = cookie.split('=' ,1 ) //这里 split 方法的第二个参数 1 表示最多分割一次,确保即使 value 中包含等号 = 也不会继续分割。 jar.set (key, value) response = requests.get(url,cookies=jar,headers=headers) print (response.text)
这里首先创建了一个RequestCookieJar对象,然后利用split方法对复制下来的Cookie内容做分割,接着利用set方法设置好每个Cookie条目的键名和键值,最后把RequestCookieJar对象通过cookies参数传递,调用requests库的get方法,即可获取登录后的页面。
Session维持 直接利用request库中的get或post方法的确可以做到模拟网页的请求,但这两种方法实际上相当于不同的Session,或者说是两个浏览器打开了不同的页面。
1 2 3 4 5 6 7 8 import requestsrequests.get('https://httpbin.org/cookies/set/number/123456789' ) r = requests.get('https://httpbin.org/cookies' ) print (r.text)>>> { "cookies" : {} }
这里请求测试网址https://httpbin.org/cookies/set/number/123456789。在请求时设置了一个Cookie条目,名称是number,内容是123456789。然后请求https://httpbin.org/cookies,获取当前Cookie信息。并不能成功获取设置的Cookie。
1 2 3 4 5 6 7 8 9 10 11 import requests S=requests.Session() S.get('https://httpbin.org/cookies/set/number/123456789') r = S.get('https://httpbin.org/cookies') print(r.text) >>> { "cookies": { "number": "123456789" } }
这样就能获取到设置的Cookie了。
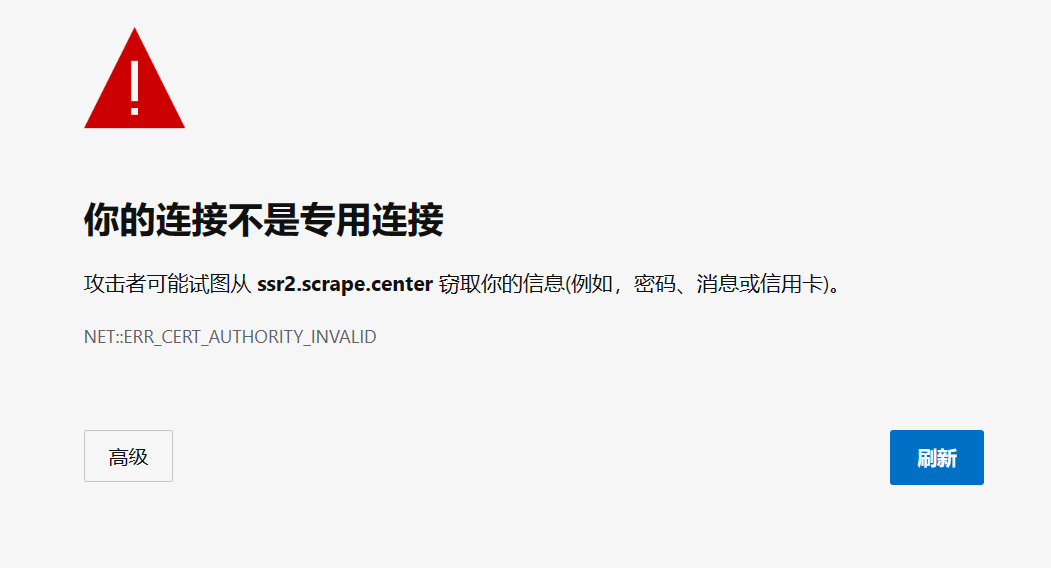
SSL证书验证 现在很多网站要求使用HTTPS协议,但有些网站可能并没有设置好HTTPS证书,或者网站的HTTPS证书可能不被CA机构认可,这些网站就可能出现SSL证书错误的提示。https://ssr2.scrape.center/,如果用Chrome浏览器打开它,会有如下提示:
1 2 3 4 import requests url = 'https://ssr2.scrape.center' response = requests.get(url) print(response.text)
会出现SSLError错误,因为我们请求的URL的证书是无效的。
1 2 3 4 5 6 7 8 import requestsurl = 'https://ssr2.scrape.center/' response = requests.get(url,verify=False ) print (response.status_code)>>> E:\JetBrains\python386\lib\site-packages\urllib3\connectionpool.py:1103 : InsecureRequestWarning: Unverified HTTPS request is being made to host 'ssr2.scrape.center' . Adding certificate verification is strongly advised. See: https://urllib3.readthedocs.io/en/latest/advanced-usage.html warnings.warn( 200
不过有警告,建议我们给它指定证书,我们可以通过设置忽略警告的方式来屏蔽这个警告。
1 2 3 4 5 6 7 8 import requestsimport urllib3url = 'https://ssr2.scrape.center/' urllib3.disable_warnings() response = requests.get(url,verify=False ) print (response.status_code)>>> 200
或捕获警告到日志的方式忽略警告:
1 2 3 4 5 6 import requestsimport loggingurl = 'https://ssr2.scrape.center/' logging.captureWarnings(True ) response = requests.get(url,verify=False ) print (response.status_code)
也可以指定一个本地证书作为客户端证书,可以是单个文件(包含密钥和证书)或一个包含两个文件路径的元组:
1 2 3 import requests response = requests.get('https://ssr2.scrape.center/' ,cert=('/path/server.crt' ,'/path/server.key' )) print (response.status_code)
这里需要有crt和key文件,并指定他们的路径,而且本地私有证书的key必须是解密状态加密状态的key是不支持的。
超时设置 在本机网络状况不好或服务器网络响应太慢甚至无响应时,我们可能会等待特别久的时间才能收到响应,甚至到最后因为接收不到响应而报错。为了防止服务器不能及时响应,可以设置一个超时时间,如果超过了这个时间还没有得到响应,就报错。
1 2 3 4 5 6 import requestsurl = 'https://httpbin.org/get' response = requests.get(url,timeout=1 ) print (response.status_code)>>> 200
如果在相应时间内没有响应就会抛出异常。response = requests.get(url,timeout=(5,30))
身份认证 在访问启用了基本身份认证的网站时,首先会弹出一个认证窗口,如前面遇到的https://ssr3.scrape.center。
1 2 3 4 5 6 7 import requestsfrom requests.auth import HTTPBasicAuthurl = 'https://ssr3.scrape.center' response = requests.get(url,auth=HTTPBasicAuth('admin' ,'admin' )) print (response.status_code)>>> 200
这个实例网站的用户名和密码都是admin,这里可以直接设置。
1 2 3 4 5 import requestsurl = 'https://ssr3.scrape.center' response = requests.get(url,auth=('admin' ,'admin' )) print (response.status_code)
还有其他认证方式,如OAuth认证,这个需要安装oauth包pip3 install requests_oauthlib
1 2 3 4 5 6 7 8 import requestsfrom requests_oauthlib import OAuth1url = 'https://ssr3.scrape.center' auth = OAuth1('YOUR_API_KEY' , 'YOUR_API_SECRET' , 'USER_OAUTH_TOKEN' ,'USER_OAUTH_TOKEN_SECRET' ) response=requests.get(url,auth=auth) print (response.status_code)
代理设置 某些网站在测试的时候请求几次,都能正常获取内容。但是一旦大规模且频繁的请求时,这些网站就可能弹出验证码,或者跳转到登录认证界面,甚至会直接封禁客户端的IP,导致在一定时间内无法访问。
1 2 3 4 5 6 7 import requestsproxies = { 'http' : 'http://10.10.10.10:1080' , 'https' : 'http://10.10.10.10:1080' } url = 'https://www.baidu.com' requests.get(url, proxies=proxies)
这里直接运行是不可以的,因为这个代理无效,可以找有效的代理替换试验。https://user:password@host:port这样的语法来设置代理:
1 2 3 4 5 import requestsproxies = { 'https' : 'http://user:password@10.10.10.10:1080' , } requests.get('https://www.httpbin.org/get' , proxies=proxies)
除了基本的HTTP代理外,requsts库还支持SOCKS协议的代理。pip3 install "requests[socks]"
1 2 3 4 5 6 import requestsproxies ={ 'http' : 'socks5://user:password@host:port' , 'https' : 'socks5://user:password@host:' } requests.get('http://www.httpbin.org/get' , proxies=proxies)
Prepared Request 我们可以直接使用requests库的get和post方法的请求,但是这个请求在requests内部是怎么实现的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 from requests import Request,Sessionurl = 'https://www.httpbin.org/post' data = { 'name' :'germy' } headers = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0' } s = Session() req = Request('POST' ,url,data=data,headers=headers) prepped = s.prepare_request(req) response = s.send(prepped) print (response.text)>>> { "args" : {}, "data" : "" , "files" : {}, "form" : { "name" : "germy" }, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Content-Length" : "10" , "Content-Type" : "application/x-www-form-urlencoded" , "Host" : "www.httpbin.org" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0" , "X-Amzn-Trace-Id" : "Root=1-663a1529-42d19be2162994625bf75e11" }, "json" : null, "origin" : "219.156.133.195" , "url" : "https://www.httpbin.org/post" }
我们引入了Request类,然后用url、data和headers参数构造了一个Request对象,这时调用Session类的prepare_request方法将其转换为Prepared Request对象,再调用send方法发送,即可达到和POST请求同样的效果。
正则表达式 实现字符串的检索、替换、匹配验证。
实例引入 正则表达式测试工具
Hello, my phone number is 010-86432100 and email is cqc@cuiqingcai.com , and my website is https://cuiqigncai.com
这段字符串包含一个电话号码,一个Email地址和一个URL,然后用正则表达式将这些内容提取出来。[a-zA-z]+://[^\s]*,a-z代表匹配任意的小写字母,\s代表匹配任意的空白字符,*代表匹配前面任意多个字符。常用匹配规则
模式
描述
\w
匹配字母数字下划线
\W
匹配非字母数字下划线
\s
匹配任意空白字符,[\t\n\r\f]
\S
匹配任意非空字符
\d
匹配任意数字,等价于[0-9]
\D
匹配任意非数字
\A
匹配字符串开头
\Z
匹配字符串结尾。如果有换行,只匹配到换行前的结束字符串
\z
匹配字符串结尾。如果有换行,同时还会匹配换行符
\G
匹配最后匹配完成的位置
\n
匹配一个换行符
\t
匹配一个制表符
^
匹配一行字符串的开头
$
匹配一行字符串的结尾
.
匹配任意字符,除了换行符。当re.DOTALL标记被指定时,可以匹配包括换行符在内的任意字符
[…]
用来表示一组字符,单独列出,如[amk]匹配a、m、k
[^…]
匹配不在[]中的字符
*
匹配0个或多个表达式
+
匹配一个或多个表达式
?
匹配0个或1个前面的正则表达式定义的片段,非贪婪方式
{n}
精确匹配n个前面的表达式
{n,m}
匹配n到m次由前面正则表达式顶一个的片段,贪婪方式
a|b
匹配a或b
()
匹配括号内的表达式,也表示一个组
正则表达式并非Python独有,但再Python的re库提供了正正则表达式的实现,利用这个库,可以再Python中方便地使用正则表达式。
match 这是一个常用的匹配方法,match方法会尝试从字符串的起始位置开始匹配正则表达式,如果匹配就返回成功的结果;否则返回None。
1 2 3 4 5 6 7 8 9 10 11 12 13 import recontent = 'Hello 123 4567 World_This is a Regex Demo' print (len (content))result = re.match ('^Hello\s\d\d\d\s\d{4}\s\w{10}' ,content) print (result)print (result.group())print (result.span())>>> 41 <re.Match object ; span=(0 , 25 ), match ='Hello 123 4567 World_This' > Hello 123 4567 World_This (0 , 25 )
首先声明字符串,^Hello\s\d\d\d\s\d{4}\s\w{10}是一个正则表达式。在match方法里,第一个参数是传入了正则表达式,第二个参数是要匹配的字符串。结果是re.Match对象,匹配成功了。对象包含两个方法:group方法可以输出匹配到的内容;span方法可以输出匹配的范围,结果是(0,25),是匹配到的结果字符串在原字符串中的位置范围。
匹配目标 match实现匹配目标,对于从字符串中提取内容,可以用括号()将想提取的子字符串括起来。()实际上标记了一个子表达式的开始和结束位置,被标记的子表达式依次对应每一个分组,通过调用group方法传入分组索引获取提取结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 import recontent = 'Hello 123 4567 World_This is a Regex Demo' result = re.match ('^Hello\s(\d\d\d\s\d{4})\s(\w{10})' ,content) print (result)print (result.group())print (result.group(1 ))print (result.span())>>> <re.Match object ; span=(0 , 25 ), match ='Hello 123 4567 World_This' > Hello 123 4567 World_This 123 4567 (0 , 25 )
把字符串中的123 4567提取出来了。group方法会输出完整的匹配结果。group(1)输出第一个被()包围的匹配结果,以此类推。
通用匹配 有一个万能匹配符,*。它可以匹配任意字符(除了换行符),*代表匹配前面的字符无限次,组合在一起就可以匹配任意字符了。
1 2 3 4 5 6 7 8 9 10 11 import re content = 'Hello 123 4567 World_This is a Regex Demo' result = re.match('^Hello.*Demo$',content) print(result) print(result.group()) print(result.span()) >>> <re.Match object; span=(0, 41), match='Hello 123 4567 World_This is a Regex Demo'> Hello 123 4567 World_This is a Regex Demo (0, 41)
中间部分全用.*代替,最后加一个结尾字符串。
贪婪与非贪婪 通用匹配.*匹配到的内容有时并不是我们想要的结果。
1 2 3 4 5 6 7 8 import recontent = 'Hello 1234567 World_This is a Regex Demo' result = re.match ('^H.*(\d+).*Demo$' ,content) print (result)print (result.group(1 ))>>> <re.Match object ; span=(0 , 40 ), match ='Hello 1234567 World_This is a Regex Demo' > 7
目标是匹配字符串中间的数字,用(\d+)来匹配数字的两侧都用.*,而结果只得到了7。.*会匹配尽可能多的字符,.*后面是\d+,至少匹配一个数字,但是这里并没有指定具体几个数字,.*就把123456都匹配了,只给\d+留下一个满足条件的7。.*?。
1 2 3 4 5 6 7 8 import recontent = 'Hello 1234567 World_This is a Regex Demo' result = re.match ('^H.*?(\d+).*Demo$' ,content) print (result)print (result.group(1 ))>>> <re.Match object ; span=(0 , 40 ), match ='Hello 1234567 World_This is a Regex Demo' > 1234567
此时成功获取了1234567。贪婪匹配是匹配尽可能多的字符,非贪婪匹配是匹配尽可能少的字符。.*?有可能匹配不到任何内容。
1 2 3 4 5 6 7 8 9 import recontent = 'Http://www.baidu.com/comment' result1 = re.match ('Http://www.baidu.com/(.*?)' ,content) result2 = re.match ('Http://www.baidu.com/(.*)' ,content) print ('result1' ,result1.group(1 ))print ('result2' ,result2.group(1 ))>>> result1 result2 comment
修饰符 在正则表达式里,可以用一些可选标志来控制匹配的模式。修饰符被指定为一个可选的标志。
1 2 3 4 5 import recontent = '''Hello 1234567 World_This is a Regex Demo''' result1 = re.match ('^He.*?(\d+).*?Demo$' ,content) print ('result1' ,result1.group(1 ))
由于字符串里加了换行符,报错了AttributeError: 'NoneType' object has no attribute 'group'。表明正则表达式没有匹配到这个字符串,结果是None。调用group方法,导致了Attribute。.*?就不能匹配了。
1 2 3 4 5 6 7 import recontent = '''Hello 1234567 World_This is a Regex Demo''' result1 = re.match ('^He.*?(\d+).*?Demo$' ,content,re.S) print (result1.group(1 ))>>> 1234567
re.S在网页匹配中经常用到。因为HTML节点经常会有换行,加上它,就可以匹配节点与节点之间的换行了。
修饰符
描述
re.I
使匹配对大小写不敏感
re.L
实现本地化识别(local-aware)匹配
re.M
多行匹配,影响^和$
re.S
使匹配内容包括换行符在内的所有字符
re.U
根据Unicode字符集解析字符。会影响\w、\W、\b、\B
re.X
给予灵活的格式,将正则表达式书写的更易于理解
转义匹配 .用于匹配除换行符以外的任意字符,但目标字符串中可能包含.这个字符。
1 2 3 4 5 6 import re content = '''(百度)www.baidu.com''' result1 = re.match('\(百度\)www\.baidu\.com',content,re.S) print(result1) >>> <re.Match object; span=(0, 17), match='(百度)www.baidu.com'>
在特殊字符前加\转义一下即可。
search match方法是从字符串的开头开始匹配的,一旦开头不匹配,整个匹配就会失败。
1 2 3 4 5 6 import recontent = 'Extra strings Hello 1234567 World_THis is a Regax Demo Strings' result = re.match ('Hello.*?(\d+).*?Demo' ,content) print (result)>>> None
match方法在使用时需要考虑目标字符串开头的内容,它更适合检测某个字符串是否符合某个正则表达式的规则。
1 2 3 4 5 6 7 8 import recontent = 'Extra strings Hello 1234567 World_THis is a Regax Demo Strings' result = re.search('Hello.*?(\d+).*?Demo' ,content) print (result)print (result.group(1 ))>>> <re.Match object ; span=(14 , 54 ), match ='Hello 1234567 World_THis is a Regax Demo' > 1234567
其他实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 html = '''<div id ="songs-list" > <h2 class ="title" > 经典老歌 </h2 > <p class ="introduction" > 经典老歌列表 </p > <ul id ="list" class ="list-group" > <li data-view ="2" > 一路上有你 </li > <li data-view ="7" > <a href ="/2.mp3" singer ="任贤齐" > 沧海一声笑 </a > </li > <li data-view ="4" class ="active" > <a href ="/3.mp3" singer ="齐秦" > 往事随风 </a > </li > <li data-view ="6" > <a href ="/4.mp3" singer ="beyond" > 光辉岁月 </a > </li > <li data-view ="5" > <a href ="/5.mp3" singer ="陈慧琳" > 记事本 </a > </li > <li data-view ="5" > <a href ="/6.mp3" singer ="邓丽君" > 但愿人长久 </a > </li > </ul > </div > '''
ul节点里有很多li节点,li节点里有点包含a节点,有的不包含a节点。a节点还有一些相应的属性——超链接和歌手名。singer="(.*?)"。接下来匹配a节点的文本,左边界是>,右边界是</a>,目标用(.*?)匹配。正则表达式就是:li.*?active.*?singer="(.*?)">(.*?)</a>。由于代码中有换行,所以search方法的第三个参数要传入re.S。:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 import rehtml = '''<div id="songs-list"> <h2 class="title"> 经典老歌 </h2> <p class="introduction"> 经典老歌列表 </p> <ul id="list" class="list-group"> <li data-view="2"> 一路上有你 </li> <li data-view="7"> <a href="/2.mp3" singer="任贤齐"> 沧海一声笑 </a> </li> <li data-view="4" class="active"> <a href="/3.mp3" singer="齐秦"> 往事随风 </a> </li> <li data-view="6"><a href="/4.mp3" singer="beyond"> 光辉岁月 </a></li> <li data-view="5"><a href="/5.mp3" singer="陈慧琳"> 记事本 </a></li> <li data-view="5"> <a href="/6.mp3" singer="邓丽君"> 但愿人长久 </a> </li> </ul> </div>''' result = re.search('li.*?active.*?singer="(.*?)">(.*?)</a>' ,html,re.S) print (result.group(1 ),result.group(2 ))>>> 齐秦 往事随风
这样就获取到了class为active的歌手名和歌曲名。
1 2 3 4 result = re.search('li.*?singer="(.*?)">(.*?)</a>' ,html,re.S) print (result.group(1 ),result.group(2 ))>>> 任贤齐 沧海一声笑
会返回第一个符合条件的匹配目标
1 2 3 4 result = re.search('li.*?singer="(.*?)">(.*?)</a>' ,html) print (result.group(1 ),result.group(2 ))>>> beyond 光辉岁月
绝大部分HTML文本包含换行符,所以要尽量加上re.s修饰符,避免出现匹配不到的问题。
findall 对于search方法,它返回与正则表达式相匹配的第一个字符串。如果想获取与正则表达式相匹配的所有字符串,要使用findall方法了。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import rehtml = '''<div id="songs-list"> <h2 class="title"> 经典老歌 </h2> <p class="introduction"> 经典老歌列表 </p> <ul id="list" class="list-group"> <li data-view="2"> 一路上有你 </li> <li data-view="7"> <a href="/2.mp3" singer="任贤齐"> 沧海一声笑 </a> </li> <li data-view="4" class="active"> <a href="/3.mp3" singer="齐秦"> 往事随风 </a> </li> <li data-view="6"><a href="/4.mp3" singer="beyond"> 光辉岁月 </a></li> <li data-view="5"><a href="/5.mp3" singer="陈慧琳"> 记事本 </a></li> <li data-view="5"> <a href="/6.mp3" singer="邓丽君"> 但愿人长久 </a> </li> </ul> </div>''' result = re.findall('li.*?href="(.*?)".*?singer="(.*?)">(.*?)</a>' ,html,re.S) print (result)print (type (result))for i in result: print (i) print (i[0 ],i[1 ],i[2 ]) >>> [('/2.mp3' , '任贤齐' , ' 沧海一声笑 ' ), ('/3.mp3' , '齐秦' , ' 往事随风 ' ), ('/4.mp3' , 'beyond' , ' 光辉岁月 ' ), ('/5.mp3' , '陈慧琳' , ' 记事本 ' ), ('/6.mp3' , '邓丽君' , ' 但愿人长久 ' )] <class 'list' > ('/2.mp3' , '任贤齐' , ' 沧海一声笑 ' ) /2. mp3 任贤齐 沧海一声笑 ('/3.mp3' , '齐秦' , ' 往事随风 ' ) /3. mp3 齐秦 往事随风 ('/4.mp3' , 'beyond' , ' 光辉岁月 ' ) /4. mp3 beyond 光辉岁月 ('/5.mp3' , '陈慧琳' , ' 记事本 ' ) /5. mp3 陈慧琳 记事本 ('/6.mp3' , '邓丽君' , ' 但愿人长久 ' ) /6. mp3 邓丽君 但愿人长久
返回列表中的每个元素都是元组类型,可以用索引依次取出每个条目。当正则表达式中只有一个分组时,列表中的元组没有()。
sub 正则表达式除了提取信息,还可以修改文本。如把字符串的所有数字都去掉,如果只用字符串的replace方法,显得繁琐,这里可以借助sub方法。
1 2 3 4 5 6 import recontent = '54aK54yr5oiR54ix5L2g' content = re.sub('\d+' ,'' ,content) print (content)>>> aKyroiRixLg
这里sub的第一个参数\d+用来匹配所有的数字,第二个参数是把数字替换成的字符串,第三个参数是原字符串。
1 2 3 4 5 6 7 8 9 10 result = re.findall('<li.*?>\s?(<a.*?>)?\s(\w+)\s(</a>)?\s?</li>' ,html,re.S) for i in result: print (i[1 ]) >>> 一路上有你 沧海一声笑 往事随风 光辉岁月 记事本 但愿人长久
显得有些繁琐,但此时用sub就很简单了。用sub把a节点去掉,只留下文本,然后用findall提取:
1 2 3 4 5 6 7 8 9 10 11 12 html = re.sub('<a.*?>|</a>' ,'' ,html) result = re.findall('<li.*?>(.*?)</li>' ,html,re.S) print (result)for i in result: print (i.strip()) >>> 一路上有你 沧海一声笑 往事随风 光辉岁月 记事本 但愿人长久
经过sub方法处理过之后,a节点就没有了,然后通过findall方法直接提取。
compile 这个方法可以将字符串编译成正则表达式对象,实现在后面的代码中复用。
1 2 3 4 5 6 7 8 9 10 11 import recontent1 = '2019-12-15 12:00' content2 = '2019-12-17 12:55' content3 = '2019-12-19 13:14' pattern = re.compile ('\d{2}:\d{2}' ) result1 = re.sub(pattern, '' , content1) result2 = re.sub(pattern, '' , content2) result3 = re.sub(pattern, '' , content3) print (result1,result2,result3)>>> 2019 -12 -15 2019 -12 -17 2019 -12 -19
这里有三个日期,我们用sub方法把日期中的时间去掉,用compile方法将正则表达式编译成一个正则表达式对象,实现复用。
httpx的使用 urllib库和requests库已经可以爬取绝大多数网站的数据,但是由于有些网站强制使用HTTP/2.0协议访问,而urllib和requests只支持HTTP/1.1,不支持HTTP2.0,就无法爬取数据。
示例 https://spa16.scrape.center/就是一个强制使用HTTP/2.0访问的一个网站。这个网站用requests库是无法爬取的:
1 2 3 4 5 6 7 8 import requestsurl = 'https://ssr1.scrape.center/' response = requests.get(url) print (response)```   会抛出错误,错误信息很多,真实原因就是requests这个库是使用HTTP/1.1 访问的目标网站,而目标网站会检测请求使用的协议是不是HTTP/2.0 ,如果不是就拒绝返回任何请求。   httpx可以使用pip3工具直接安装,需要的Python版本是3.6 及以上
pip3 install httpx
1 但是这样安装完的httpx是不支持HTTP/2.0的,如果想支持,可以这样安装
pip3 install “httpx[http2]”
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 就既安装了httpx,又安装了httpx对HTTP/2.0的支持模块。 ## 基本使用   基本GET请求用法 ```py import httpx response = httpx.get('https://httpbin.org/get') print(response.status_code) print(response.headers) print(response.text) >>> 200 Headers({'date': 'Mon, 13 May 2024 03:59:08 GMT', 'content-type': 'application/json', 'content-length': '306', 'connection': 'keep-alive', 'server': 'gunicorn/19.9.0', 'access-control-allow-origin': '*', 'access-control-allow-credentials': 'true'}) { "args": {}, "headers": { "Accept": "*/*", "Accept-Encoding": "gzip, deflate", "Host": "httpbin.org", "User-Agent": "python-httpx/0.27.0", "X-Amzn-Trace-Id": "Root=1-6641900c-25c2aaf626555ab94c910e08" }, "origin": "219.156.133.195", "url": "https://httpbin.org/get" }
输出有状态码,响应头,响应体。,可以在响应体里看到User-Agent是python-httpx/0.27.0,代表是httpx请求的。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import httpxheaders = { 'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0' } response = httpx.get('https://www.httpbin.org/get' ,headers=headers) print (response.text)>>> { "args" : {}, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Host" : "www.httpbin.org" , "User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36 Edg/124.0.0.0" , "X-Amzn-Trace-Id" : "Root=1-664192eb-4fab4c527b08851818d180d9" }, "origin" : "219.156.133.195" , "url" : "https://www.httpbin.org/get" }
接下来使用httpx请求https://spa16.scrape.center/这个http/2.0的网站
1 2 3 4 import httpxurl = 'https://spa16.scrape.center/' response = httpx.get(url) print (response.text)
还是会抛出错误,其实httpx默认是不会开启对HTTP/2.0的支持的,默认使用的是HTTP/1.1,需要手动声明一下才能使用HTTP/2.0
1 2 3 4 5 import httpxclient = httpx.Client(http2=True ) url = 'https://spa16.scrape.center/' response = client.get(url) print (response.text)
1 2 3 4 5 6 7 import httpx r=httpx.get('https://spa16.scrape.center/get',params={'name','germy'}) r=httpx.post('https://spa16.scrape.center/post',data={'name','germy'}) r=httpx.put('https://spa16.scrape.center/put') r=httpx.delete('https://spa16.scrape.center/delete') r=httpx.patch('https://spa16.scrape.center/patch')
根据得到的Response对象,使用以下属性和方法获取想要的内容。
status_code:状态码
text: 响应体的文本内容
content: 响应体的二进制内容
headers: 响应头,是headers对象,可以用像获取字典中的内容一样获取其中某个Header的值。
json:方法,调用此方法将文本结果转化为JSON对象。
可以参考httpx官方文档
Client对象 httpx中有一个Client对象,可以和requests中的Session对象类比学习。
1 2 3 4 5 6 7 import httpxwith httpx.Client() as client: response = client.get('https://www.httpbin.org/get' ) print (response) >>> <Response [200 OK]>
这种用法等价于:
1 2 3 4 5 6 7 8 import httpxclient = httpx.Client() try : response = client.get('http://httpbin.org' ) finally : client.close() print (response)
这两种方式的运行结果一样,这里需要在最后显式调用close方法来关闭Client对象。
1 2 3 4 5 6 7 8 import httpx url = 'https://www.httpbin.org/headers' headers = {'User-Agent': 'my-app/0.0.1'} with httpx.Client(headers=headers) as client: r=client.get(url) print(r.json()['headers']['User-Agent']) >>> my-app/0.0.1
这里声明了headers变量,内容为User-Agent属性,然后将此变量传递给headers参数初始化一个Client对象,赋值给client变量,用client变量请求测试网站,打印User-Agent内容。官方文档 。
支持HTTP/2.0 要声明Client对象,然后将http2参数设置为True,如果不设置,就默认支持HTTP/1.1,是不能开启对HTTP/2.0的支持。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import httpxclient = httpx.Client(http2=True ) url = 'https://www.httpbin.org/get' response = client.get(url) print (response.text)print (response.http_version)>>> { "args" : {}, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Host" : "www.httpbin.org" , "User-Agent" : "python-httpx/0.27.0" , "X-Amzn-Trace-Id" : "Root=1-6641b1c0-03c067ce641ca1223c927bb3" }, "origin" : "219.156.133.195" , "url" : "https://www.httpbin.org/get" } HTTP/2
我们输出了response变量的http_version属性,这时request中不存在的属性。
客户端的httpx上启用对HTTP/2.0的支持并不意味着请求和响应都通过HTTP/2.0传输。需要客户端和服务端都支持HTTP/2.0才可以。
支持异步请求 httpx还支持异步客户端请求(AsyncClient),支持Python的async请求模式。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import httpximport asyncioasync def fetch (url ): async with httpx.AsyncClient(http2=True ) as client: response = await client.get(url) print (response.text) if __name__ == '__main__' : asyncio.get_event_loop().run_until_complete(fetch('https://www.httpbin.org/get' )) >>> { "args" : {}, "headers" : { "Accept" : "*/*" , "Accept-Encoding" : "gzip, deflate" , "Host" : "www.httpbin.org" , "User-Agent" : "python-httpx/0.27.0" , "X-Amzn-Trace-Id" : "Root=1-6641b38e-6d8e79bb0d6cf9c909831d2f" }, "origin" : "219.156.133.195" , "url" : "https://www.httpbin.org/get" }
这里了解即可。详细可参考官方文档
基础实例案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 import requestsimport logging import refrom urllib.parse import urljoinimport jsonfrom os import makedirsfrom os.path import existsRESULT_DIR = 'result' exists(RESULT_DIR) or makedirs(RESULT_DIR) BASE_URL = 'https://ssr1.scrape.center' TOTAL_PAGE = 10 detail_url=[] def scrape_page (url ): logging.info('scraping %s ...' ,url) try : response = requests.get(url) if response.status_code == 200 : return response.text else : logging.error('get invalid status code %s while scraping %s' ,response.status_code,url) except requests.RequestException: logging.error('error occurred while scraping %s' ,url,exc_info=True ) def scrape_idnex (page ): index_url = urljoin(BASE_URL,"/page/" +str (page)) return index_url def parse_index (html ): pattern = re.compile ('<a.*?href="(.*?)" class="name">' ) items = re.findall(pattern,html) if not items: return [] else : for item in items: detail_url.append(urljoin(BASE_URL,item)) logging.info('get detail url %s' ,urljoin(BASE_URL,item)) def scrape_detail (url ): return scrape_page(url) def parse_detail (html ): cover_pattern = re.compile ('id="detail".*?<a.*?>.*?<img.*?"".*?src="(.*?)".*?class="cover">.*?</a>' , re.S) name_pattern = re.compile ('<h2.*?>(.*?)</h2>' ) categories_pattern = re.compile ('<button.*?category.*?>.*?<span>(.*?)</span>.*?</button>' , re.S) info_time_pattern = re.compile ('<div.*?info">.*?<span.*?>(\d{4}-\d{2}-\d{2}) 上映</span>.*?</div>' ,re.S) score_pattern = re.compile ('<p.*?score.*?>(.*?)</p>' ,re.S) drama_pattern = re.compile ('<div.*?class="drama"><h3.*?>剧情简介</h3>.*?<p.*?>(.*?)</p></div>' ,re.S) cover = re.search(cover_pattern,html).group(1 ).strip() if re.search(cover_pattern,html) else None name = re.search(name_pattern,html).group(1 ).strip() if re.search(name_pattern,html) else None categories = re.findall(categories_pattern,html) if re.findall(categories_pattern,html) else None info_time = re.search(info_time_pattern,html).group(1 ) if re.search(info_time_pattern,html) else None score = re.search(score_pattern,html).group(1 ).strip() if re.search(score_pattern,html) else None drama = re.search(drama_pattern,html).group(1 ).strip() if re.search(drama_pattern,html) else None return { 'cover' :cover, 'name' : name, 'categories' : categories, 'info_time' : info_time, 'score' : score, 'drama' :drama } def save_data (data ): name = data.get('name' ) data_path = f'{RESULT_DIR} /{name} .json' json.dump(data,open (data_path,'w' ,encoding='utf-8' ),ensure_ascii=False ,indent=2 ) def main (): for page in range (1 ,TOTAL_PAGE+1 ): page_index=scrape_idnex(page) html=scrape_page(page_index) parse_index(html) for items in detail_url: print (items) html_detail=scrape_page(items) detail=parse_detail(html_detail) save_data(detail) if __name__ == '__main__' : main()